CUDA
ALso visit Jonathan Hui’s CUDA tutorial
Host and Device
-
Host = CPU Device = GPU
-
Using
globalto declare a function as device code Runs on device Called from host
Let’s consider a sample CUDA program from here
#include<stdio.h>
#include<cuda.h>
#include<cuda_runtime_api.h>
__global__ void AddIntsCUDA(int * a, int * b) //Kernel Definition
{
* a = * a + * b;
}
int main() {
int a = 5, b = 9;
int * d_a, * d_b; //Device variable Declaration
//Allocation of Device Variables
cudaMalloc((void ** ) & d_a, sizeof(int));
cudaMalloc((void ** ) & d_b, sizeof(int));
//Copy Host Memory to Device Memory
cudaMemcpy(d_a, & a, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, & b, sizeof(int), cudaMemcpyHostToDevice);
//Launch Kernel
AddIntsCUDA << < 1, 1 >> > (d_a, d_b);
//Copy Device Memory to Host Memory
cudaMemcpy( & a, d_a, sizeof(int), cudaMemcpyDeviceToHost);
printf("The answer is ", a);
//Free Device Memory
cudaFree(d_a);
cudaFree(d_b);
return 0;
}
-
cudaMallocSame as malloc, allocates memory on the GPU -
cudaFreeMemory allocated bycudaMallocmust be freed to avoid memory leaks -
cudaMemcpyArguments are : destination, source, size, mode Mode can be eithercudaMemcpyHostToDeviceORcudaMemcpyDeviceToHost
Basic device memory management
cudaMalloc()
cudaMemcpy()
cudaFree()
Launching parallel kernels
AddIntsCUDA << < 1, 1 >> > (d_a, d_b); is launched with 1 block and 1 thread respectively.
AddIntsCUDA<<<blocks, threads>>>
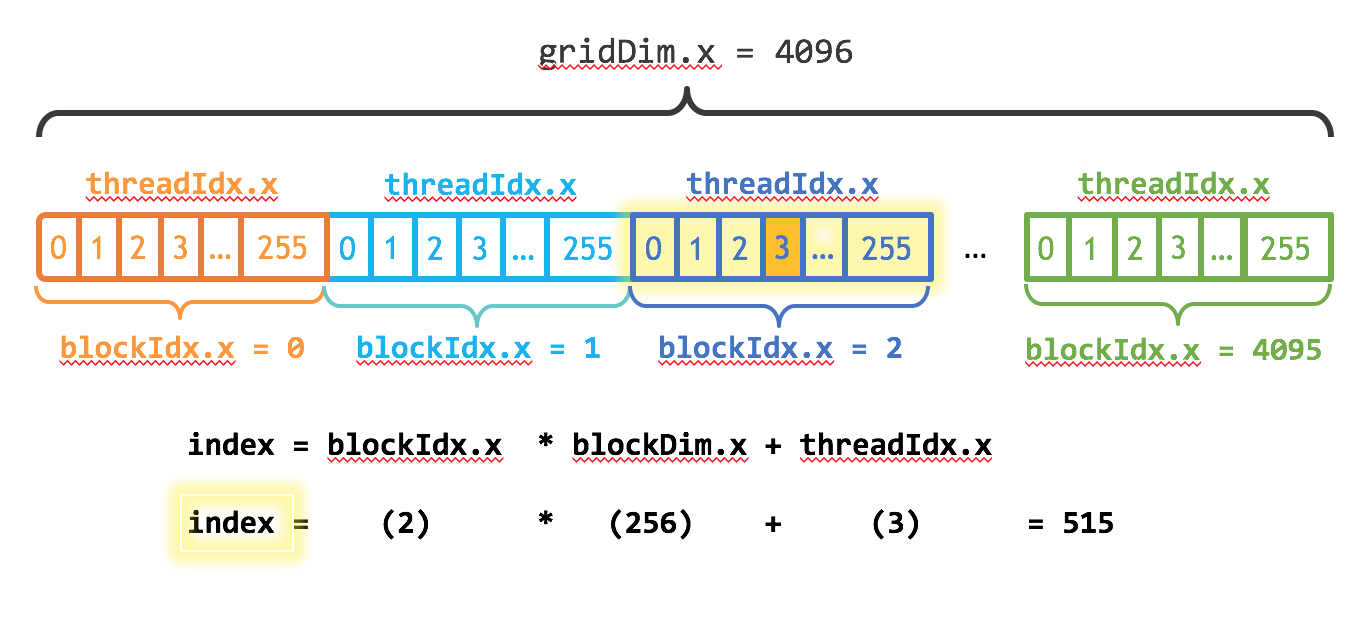
Threads and Blocks
Used blockIdx.x to access block’s index
Visit this link for a cheatsheet on threads and blocks
Sample Programs
- Parallel Array Sum
#define N (2048*2048)
#define THREADS_PER_BLOCK 512
__global__ void add( int *a, int *b, int *c ) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
c[index] = a[index] + b[index];
}
main(){
...
add<<< N/THREADS_PER_BLOCK, THREADS_PER_BLOCK >>>( dev_a, dev_b, dev_c );
}
- Shared Memory
/**
* @param a , @param b are pointers to input arrays
* @param c is a pointer to an int variable that will hold the result
* */
__global void add(int *a, int *b, int *c){
__shared__ int temp[N];
temp[threadId.x] = a[ threadId.x ] * b[ threadId.x ];
__syncthreads();
if(threadId.x == 0){
int sum = 0;
for(int i=0;i<N;i++){
sum+= temp[i];
}
*c = sum;
}
}
- 2D Matrix Multiplication
__global__ void simpleMatMulKernell(float* d_M, float* d_N, float* d_P, int width)
{
int row = blockIdx.y*width+threadIdx.y;
int col = blockIdx.x*width+threadIdx.x;
if(row<width && col <width) {
float product_val = 0
for(int k=0;k<width;k++) {
product_val += d_M[row*width+k]*d_N[k*width+col];
}
d_p[row*width+col] = product_val;
}
}